Communicated by Dr. Yuxiao Yang
December 2021
Shixian Wen1, Laurent Itti1
Department of Computer Science, University of Southern California, Los Angeles, California1
Lifelong learning challenges
The human brain can quickly learn and adapt its behavior in a wide range of environments throughout its lifetime. In contrast, deep neural networks only learn one sophisticated but fixed mapping from inputs to outputs. In more complex and dynamic scenarios where the inputs to outputs mapping may change with different contexts, the deployment of these deep neural network systems would be constrained. One of the failed salient scenarios is lifelong learning1—learning new independent tasks sequentially without forgetting previous tasks. More specifically, agents should incrementally learn and evolve based on multiple tasks from various data distributions across time while remembering previously learned knowledge. In general, current neural networks are not capable of lifelong learning and usually suffer from “catastrophic forgetting”2,3—learning the knowledge of the new task would overwrite the fixed learned mapping of an old task. This effect typically leads to a significant decrease of the network performances on previous tasks or, in the worst case, leads to the network completely forgetting all previous tasks.
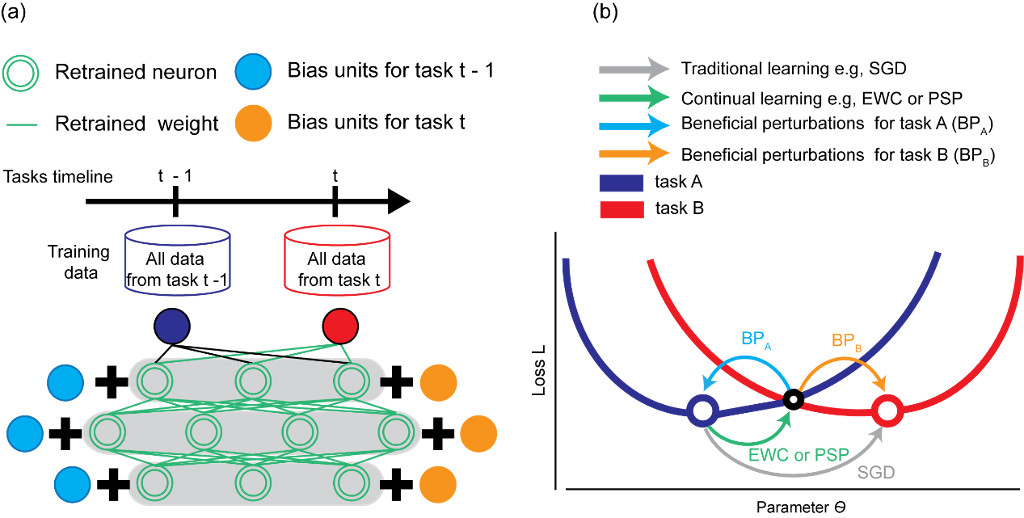
Figure 1 (a) Beneficial Perturbation Networks (BPN). BPN creates beneficial perturbations for each task and stores them into task-dependent bias units. When learning or testing a task, the corresponding bias units are activated. It biases the network toward that task and thus allows it to operate into different independent parallel universes for processing different tasks. The normal weights are retrained by using EWC or PSP. (b) At runtime, BPN can switch into various task-optimal network parameters. Training trajectories for different methods are illustrated in parameter and loss space. The dark blue (red) curve and the circle represent the loss as a function of network parameters and the optimal parameters for task A, respectively (B). After learning the first task A, the parameters are optimal for task A (dark blue circle). Then if we train the same network on task B with stochastic gradient descend (SGD, have no constraints on parameters, gray), we will minimize the loss for task B (red circle) but destroy the knowledge learned from task A. If, instead, we use EWC or PSP to constrain the same network when learning on task B (have some constraints on parameters, green), we end up with a compromised solution that is sub-optimal for both tasks (black circle). Beneficial perturbations (task A – light blue curve, task B – orange curve for task B) push the sub-optimal representation learned by EWC or PSP back to their task-optimal states. Figure adapted from Wen et al.4
Beneficial Perturbation Network (BPN)
Our recent work reported in Wen et al.4 addresses catastrophic forgetting by proposing a new brain-inspired method—Beneficial Perturbation Network (Fig. 1.a)—to accommodate dynamic learning scenarios. The main contribution of our work is to enable one neural network to learn potentially unlimited mappings and switch between them at runtime. To achieve lifelong learning, we use existing lifelong learning methods (parameter superposition (PSP5) or elastic weight consolidation (EWC6)) to reduce the catastrophic interference between sequential tasks. Then, we add bias units to the network. These units are out of network, so they do not receive the input stimulus like the other units in the network; they just provide a fixed bias, but the bias is task-dependent. We leverage a reverse adversarial attack to calculate the most beneficial task-dependent bias—beneficial perturbations. In adversarial attack7, adding imperceptible adversarial perturbations to natural inputs can force the machine learning models into misclassifications. In contrast, beneficial perturbations in the parameter space can assist machine learning models in making correct classifications. Beneficial perturbations reinforce the current task by pushing the drifted representation back to their task-optimal states (Fig.1.b). Essentially, one can think of bias units as providing different carrier frequencies or DC-offset to the network. In this sense, bias units enable the network to operate into different independent parallel universes; when we are under different tasks, the bias units will decouple that particular task from the other tasks.
Biological Inspiration of BPN
As a similarity in neuroscience, the Hippocampus (HPC8) leverages task-dependent long-term memories to operate into different modes to process different tasks. During weight consolidation9,10, HPC uses sparse representations and a high learning rate to store memory traces for each task without catastrophic interference from other tasks. Gradually, when memories mature, the HPC progressively teaches and transfers these experiences to neocortical regions11. Gradually, neocortical regions have learned long-term memories by extracting and representing regularities across experiences. When a specific memory is in need, the HPC can retrieve them independently.
HPC of the human brain provides some inspiration to formulate our BPN. During the sequential learning of multiple tasks on BPN, normal weights updated by PSP or EWC, in theory, lead to non-overlapping representation for each task (similar to non-overlapping representations of the stored memory traces in HPC). However, It’s inevitable to incur some aliasing across these representations. Often, the unrealized capacity of the core network diminishes as the number of tasks increases. Therefore, once the required capacity of the new task exceeds the unrealized capacity, a portion of capacity from previous tasks would be reassigned to the new task. To overcome this effect, we have task-dependent bias units, which operate similarly as neocortical areas to store task-dependent long-term memories. During testing, the bias units corresponding to the current task are activated to reinforce the current task, which operates similarly as the HPC to retrieve the corresponding long-term memory when a specific memory is needed.

Figure 2 (a) Test accuracy of various methods training on the Eight Sequential Object Recognition Datasets. (b) Results for 100 permuted MNIST Datasets. The average task accuracy of all tasks trained so far as the number of tasks increases. Figure adapted from Wen et al.4
Results
We first show that BPN achieved superior performance across different domains and datasets. To demonstrate this, we tested our BPN on a sequence of eight object recognition datasets4 (Flower, Scenes, Birds, Cars, Aircraft, Action, Letters, SVHM). In Fig.2.a, we demonstrated that BPN (BD + PSP or BD + EWC) achieves superior performance compared to the state-of-the-art (IMM12,LwF13,EWC6,SI14,MAS15,PSP5). Compared to using PSP or EWC alone, the performance increases significantly by including the BD component (black arrows in Fig.1.a).
We next show that BPN can accommodate a large number of tasks. To demonstrate this, we tested our BPN on 100 permuted MNIST datasets4. We used a network with 4 fully connected layers. Each layer has 128 ReLu units. This network was tiny and did not have a large enough unrealized capacity for accommodating 100 permuted MNIST datasets. Thus, the deployment of PSP or EWC on this network structure was discouraging. In Fig. 2.b, after learning 100 permuted MNIST tasks, the average task performance of PSP was 30.14 percent worse than BD + PSP. The average task performance of EWC was 35.47 percent worse than BD + EWC.
Summary
We proposed a new brain-inspired neural network—the Beneficial Perturbation Network. Our BPN can operate into different parallel universes to process different independent tasks. We have successfully applied BPN to the lifelong learning scenario. Our experiments demonstrated that (i) compared to the state-of-the-art, our BPN achieved superior performance across different domains and datasets; (ii) BPN has room to accommodate a large number of tasks.
References
- Parisi, G. I., Kemker, R., Part, J. L., Kanan, C. & Wermter, S. Continual lifelong learning with neural networks: A review. Neural Networks (2019) doi:10.1016/j.neunet.2019.01.012.
- French, R. M. Dynamically constraining connectionist networks to produce distributed, orthogonal representations to reduce catastrophic interference. in Proceedings of the Sixteenth Annual Conference of the Cognitive Science Society (2019). doi:10.4324/9781315789354-58.
- McCloskey, M. & Cohen, N. J. Catastrophic Interference in Connectionist Networks: The Sequential Learning Problem. Psychol. Learn. Motiv. – Adv. Res. Theory (1989) doi:10.1016/S0079-7421(08)60536-8.
- Wen, S., Rios, A., Ge, Y. & Itti, L. Beneficial Perturbation Network for Designing General Adaptive Artificial Intelligence Systems. IEEE Trans. Neural Networks Learn. Syst. (2021) doi:10.1109/TNNLS.2021.3054423.
- Cheung, B., Terekhov, A., Chen, Y., Agrawal, P. & Olshausen, B. Superposition of many models into one. in Advances in Neural Information Processing Systems (2019).
- Kirkpatrick, J. et al. Overcoming catastrophic forgetting in neural networks. Proc. Natl. Acad. Sci. U. S. A. (2017) doi:10.1073/pnas.1611835114.
- Florian Tramèr, Nicolas Papernot, Ian Goodfellow, D. B. P. M. The Space of Transferable Adversarial Examples. in arXiv.1704.03453 (2017).
- Bakker, A., Kirwan, C. B., Miller, M. & Stark, C. E. L. Pattern separation in the human hippocampal CA3 and dentate gyrus. Science (80-. ). (2008) doi:10.1126/science.1152882.
- Lesburguères, E. et al. Early tagging of cortical networks is required for the formation of enduring associative memory. Science (80-. ). (2011) doi:10.1126/science.1196164.
- Squire, L. R. & Alvarez, P. Retrograde amnesia and memory consolidation: a neurobiological perspective. Curr. Opin. Neurobiol. (1995) doi:10.1016/0959-4388(95)80023-9.
- Schapiro, A. C., Turk-Browne, N. B., Botvinick, M. M. & Norman, K. A. Complementary learning systems within the hippocampus: A neural network modelling approach to reconciling episodic memory with statistical learning. Philos. Trans. R. Soc. B Biol. Sci. (2017) doi:10.1098/rstb.2016.0049.
- Lee, S. W., Kim, J. H., Jun, J., Ha, J. W. & Zhang, B. T. Overcoming catastrophic forgetting by incremental moment matching. in Advances in Neural Information Processing Systems (2017).
- Li, Z. & Hoiem, D. Learning without Forgetting. IEEE Trans. Pattern Anal. Mach. Intell. (2018) doi:10.1109/TPAMI.2017.2773081.
- Zenke, F., Poole, B. & Ganguli, S. Continual learning through synaptic intelligence. in 34th International Conference on Machine Learning, ICML 2017 (2017).
- Aljundi, R., Babiloni, F., Elhoseiny, M., Rohrbach, M. & Tuytelaars, T. Memory Aware Synapses: Learning What (not) to Forget BT – Computer Vision – ECCV 2018. Eccv (2018).
Author Biographies
 Shixian Wen received his B.Sc. degree in Telecommunication Engineering from the Beijing Jiaotong University (Beijing, China) in 2015, B.Sc. degree in Computer Science from Mid Sweden University (Sundsvall, Sweden) in 2015, and his M.Sc, degree in Computer Science from University of Southern California (Los Angeles, United States) in 2017. He is currently a Ph.D. Candidate in Computer Science with the Dr. Laurent Itti group, from University of Southern California. He is very interested in designing bio-inspired machine learning systems and discovering the secrets of the brain functions with machine learning techniques. His current interests include: Lifelong Learning, Adversarial Examples, Network with Attention and Brain Machine Interfaces.
Shixian Wen received his B.Sc. degree in Telecommunication Engineering from the Beijing Jiaotong University (Beijing, China) in 2015, B.Sc. degree in Computer Science from Mid Sweden University (Sundsvall, Sweden) in 2015, and his M.Sc, degree in Computer Science from University of Southern California (Los Angeles, United States) in 2017. He is currently a Ph.D. Candidate in Computer Science with the Dr. Laurent Itti group, from University of Southern California. He is very interested in designing bio-inspired machine learning systems and discovering the secrets of the brain functions with machine learning techniques. His current interests include: Lifelong Learning, Adversarial Examples, Network with Attention and Brain Machine Interfaces.
 Laurent Itti received his M.S. degree in Image Processing from the Ecole Nationale Superieure des Telecommunications (Paris, France) in 1994, and his Ph.D. in Computation and Neural Systems from Caltech (Pasadena, California) in 2000. He has since then been an Assistant, Associate, and now Full Professor of Computer Science, Psychology, and Neuroscience at the University of Southern California. Dr. Itti’s research interests are in biologically-inspired computational vision, in particular in the domains of visual attention, scene understanding, control of eye movements, and surprise. This basic research has technological applications to, among others, video compression, target detection, and robotics. Dr. Itti has co-authored over 150 publications in peer-reviewed journals, books and conferences, three patents, and several open-source neuromorphic vision software toolkits.
Laurent Itti received his M.S. degree in Image Processing from the Ecole Nationale Superieure des Telecommunications (Paris, France) in 1994, and his Ph.D. in Computation and Neural Systems from Caltech (Pasadena, California) in 2000. He has since then been an Assistant, Associate, and now Full Professor of Computer Science, Psychology, and Neuroscience at the University of Southern California. Dr. Itti’s research interests are in biologically-inspired computational vision, in particular in the domains of visual attention, scene understanding, control of eye movements, and surprise. This basic research has technological applications to, among others, video compression, target detection, and robotics. Dr. Itti has co-authored over 150 publications in peer-reviewed journals, books and conferences, three patents, and several open-source neuromorphic vision software toolkits.