Yuanning Li1 and Edward F. Chang2
1 School of Biomedical Engineering & State Key Laboratory of Advanced Medical Materials and Devices, ShanghaiTech University, Shanghai, 201210, China
2 Department of Neurological Surgery, University of California, San Francisco, California, 94143, USA
Correspondence to: Edward F. Chang (edward.chang@ucsf.edu)
Speech communication accounts for a significant amount of the social interactions in daily life. Neurological conditions like amyotrophic lateral sclerosis, stroke, brain tumor and traumatic brain injury can lead to the paralysis or impairment of the vocal structures responsible for speech production. For these patients, restoring speech functioning is one of the crucial components for their rehabilitation. Currently in the realm of speech prosthetic devices, the prevailing approach largely centers on augmentative and alternative communication (AAC) devices. Patients typically engage with these devices by issuing commands via motion-sensing or eye-tracking techniques [1]. Nevertheless, these alternatives inherently introduce an indirect mode of communication. In comparison to the fluidity of natural vocal interaction, users must initially translate their intended speech into a sequence of motor commands or eye movements, such as clicking and typing, to facilitate language output for communication. This intermediate step adds a substantial cognitive load to the process, resulting in communication that is less intuitive, more susceptible to errors, and burdened with increased complexity. Consequently, there is a pressing need to advance the development of speech prosthetics that closely emulate naturalistic speech communication while imposing minimal additional cognitive demands on the users.
Speech brain-computer interface (BCI) represents an innovative and promising technology designed to decode brain signals directly into speech language [2]. For patients with speech deficits, this technology offers them a means to engage in naturalistic communication without additional exertion like traditional AACs. In recent years, several pioneering studies have underscored the feasibility of extracting speech language information from direct intracranial neural recordings in patients with paralysis [3]–[5]. These breakthroughs primarily leverage insights into the neural mechanisms governing speech production. The sensorimotor cortex, for instance, features spatiotemporal coding that encapsulates the muscular actions within the vocal tract responsible for the articulatory gestures fundamental to speech production, such as coordinated lips and tongue movements [6], [7], or the trajectory of hand movements during letter handwriting [5]. By capturing these sequences of neural signals and translating the patterns of neural activity into linguistic units, such as letters, phonemes, or words, the system can effectively transform the “thoughts” of speech into written language. Consequently, individuals with paralysis can employ these systems to communicate through a BCI, generating text output at a rate of approximately 15 words or 90 characters per minute, a performance on par with standard touchscreen typing using a QWERTY keyboard.
Despite these remarkable advances, several noteworthy limitations persist within these prototype systems. First, to attain a level of naturalistic communication speed, these systems must achieve a rate of approximately 100 words per minute, which corresponds to a 5x speed-up compared to these previous studies. Second, previous systems have relatively small vocabulary or rely on combinations of single letters to achieve large vocabulary, which diverge from real natural communications. Third, it is important to acknowledge that a substantial portion of human communication, estimated to be around 90%, occurs nonverbally, relying on vocal cues like pitch and nonverbal cues such as facial expressions [8]. Consequently, it is evident that there is a compelling need to develop speech BCIs that not only attain naturalistic communication speeds with a larger vocabulary but also encompass multimodal output, extending beyond text to include speech audio and facial expressions, thereby more faithfully replicating the complexities of human interaction.
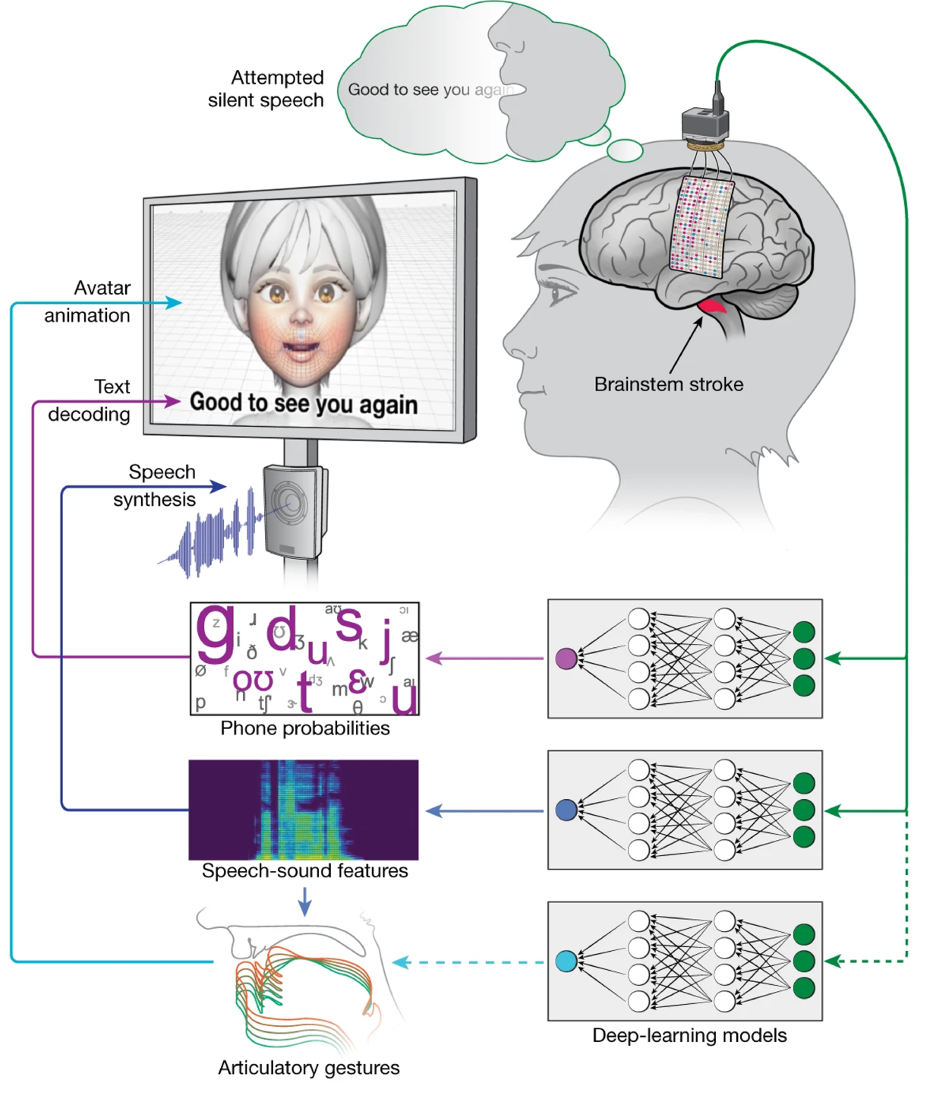
In a recent study featured in the journal Nature [9], Metzger and colleagues developed such a novel high-speed speech BCI system equipped with avatar control. In their experiment, the researchers surgically implanted a customized 253-channel high-density electrocorticography (ECoG) array in a patient with anarthria after suffering a brainstem-stroke 18 years ago. The electrode array covers critical speech-related cortical areas, mainly including the sensorimotor cortex and the superior temporal gyrus (Figure 1). The ECoG array records local field potentials that reflect the neuronal firing patterns within the population of neurons when the patient attempts to silently articulate sentences displayed on a screen. After pre-amplifying and digitizing, the signals are used to train three different types of decoders based on deep neural networks (DNNs; Figure 1):
- Text decoder: the first DNN model decodes ECoG signal into discrete phoneme sequence. The phoneme sequences are subsequently decoded into words using connectionist temporal classification (CTC) beam search, and the words are further refined into the most likely sentence using an n-gram language model.
- Audio decoder: the second DNN model translates ECoG signals into a mel spectrogram, which is then synthesized into speech audio utilizing a vocoder. To make the synthesized audio even more remarkable, a voice-conversion model is employed to transform it to the patient’s personal voice according to audio-recordings prior to the brain injury.
- Face-avatar decoder: The third DNN model decodes the ECoG signals into articulatory trajectories governing the movements of the tongue, jaw, and lips. These trajectories are then passed into a pretrained gesture-animation model, which animates the facial movements of an avatar within a virtual environment.
Putting all these decoders together, the authors demonstrate that the multimodal speech-neuroprosthetic approach achieves ~80 words per minute speech decoding with less than 25% word error rate. Moreover, it facilitates the synthesis of intelligible and personalized speech audio and enables the animated representation of orofacial movements, both for speech and non-speech communicative gestures, using a virtual avatar. Such system significantly improves the patient’s communication ability and quality of life by increasing expressivity, independence and productivity through the multimodal naturalistic speech communications.
This study represents a significant advancement in speech neuroprosthetic devices. As we move towards fully naturalistic multimodal communications, there are several challenges remain to be addressed. From the hardware perspective, the current state of the art involves the recording of signals using custom high-density electrocorticography (ECoG) grids. Recent research has also shown the potential for high-speed speech text decoding via single-unit recordings obtained through implanted Utah arrays [10]. Future studies remain to be done to develop more advanced neural electrode interface that shed light on large-scale chronic brain activity with minimal disruption to the neural environment. Such advances in materials and electronics would undoubtfully enhance the performance of speech BCIs. At the algorithm level, the current prototypes presented in recent studies all based on implementations in few patients and highly customized decoding algorithms. The challenge now lies in making these algorithms generalizable to more extensive patient populations, an endeavor that merits exploration in future investigations jointly with advances in AI technology. From a neuroscientific point of view, the current speech BCI decoding are predominantly driven by the neural coding of articulatory movements. However, for individuals with impairments affecting the sensorimotor cortex, the decoding of more abstract or higher-level linguistic representations becomes imperative for effective speech communication. The development of theories and methods to decode such information remains an intriguing avenue for future research in both language neuroscience and neuroengineering. These challenges, spanning hardware, algorithmic, and neuroscientific domains, underscore the exciting opportunities and directions in advancing the field of speech prosthetic devices and speech brain-computer interfaces.
References:
[1] R. W. Schlosser, The efficacy of augmentative and alternative communication, vol. 1. Brill, 2023.
[2] J. S. Brumberg, A. Nieto-Castanon, P. R. Kennedy, and F. H. Guenther, “Brain–computer interfaces for speech communication,” Speech Commun., vol. 52, no. 4, pp. 367–379, 2010.
[3] D. A. Moses et al., “Neuroprosthesis for decoding speech in a paralyzed person with anarthria,” N. Engl. J. Med., vol. 385, no. 3, pp. 217–227, 2021.
[4] S. L. Metzger et al., “Generalizable spelling using a speech neuroprosthesis in an individual with severe limb and vocal paralysis,” Nat. Commun., vol. 13, no. 1, p. 6510, 2022.
[5] F. R. Willett, D. T. Avansino, L. R. Hochberg, J. M. Henderson, and K. V. Shenoy, “High-performance brain-to-text communication via handwriting,” Nature, vol. 593, no. 7858, pp. 249–254, 2021.
[6] K. E. Bouchard, N. Mesgarani, K. Johnson, and E. F. Chang, “Functional organization of human sensorimotor cortex for speech articulation,” Nature, vol. 495, no. 7441, pp. 327–332, 2013.
[7] J. Chartier, G. K. Anumanchipalli, K. Johnson, and E. F. Chang, “Encoding of articulatory kinematic trajectories in human speech sensorimotor cortex,” Neuron, vol. 98, no. 5, pp. 1042-1054. e4, 2018.
[8] B. Pease and A. Pease, The definitive book of body language: The hidden meaning behind people’s gestures and expressions. Bantam, 2008.
[9] S. L. Metzger et al., “A high-performance neuroprosthesis for speech decoding and avatar control,” Nature, pp. 1–10, 2023.
[10] F. R. Willett et al., “A high-performance speech neuroprosthesis,” Nature, pp. 1–6, 2023.
Figure 1 Overview of the multimodal speech brain computer interface pipeline. A customized 253-channel high-density electrocorticography (ECoG) array is surgically implanted in a patient with anarthria after suffering a brainstem-stroke 18 years ago. Neural activity recorded from the ECoG array is preprocessed and used to train DNN models to predict phoneme probabilities, mel spectrogram and articulatory gestures of tongue, lips and jaw. These multistream decoding outputs are used to decode text, synthesize speech audio and animate a virtual avatar, respectively. (Figure adapted from [9]).